Hoeveel data mag je verliezen en hoe lang kan je zonder? In database land een aloude vraag, beter bekend onder de noemer RTO/RPO. Echter geldt het in deze tijd van cloud en data oplossingen nog steeds voor data en bedrijfsprocessen. Als een systeem of platform crashed, gehackt wordt of de data corrupt raakt en hersteld moet worden, dien je voor jezelf twee vragen te beantwoorden.
-
Hoeveel data mag je kwijt raken?
-
Hoe lang mag het duren voordat de data weer beschikbaar is?
Praktische uitleg
Als je iedere nacht een backup maakt en je systeem crashed aan het einde van de middag. Is het dan acceptabel om terug te gaan naar de situatie van gisterenavond? Kortom, hoeveel data ben je dan kwijt? Stel, je systeem crashed en de hersteltijd voor het terug zetten van backup is 4 uur. Dan, afgezien van de data situatie ‘terug draaien in de tijd’, ben je ook nog eens een bepaalde tijd niet beschikbaar. Wat kost het je dan, aan bijvoorbeeld manuren omdat mensen niet kunnen werken. Het reikt uiteraard verder want voor je klanten ligt je dienst dan ook stil. Denk daarbij onder andere ook aan imago schade of juridische risico’s.
Altijd aan!
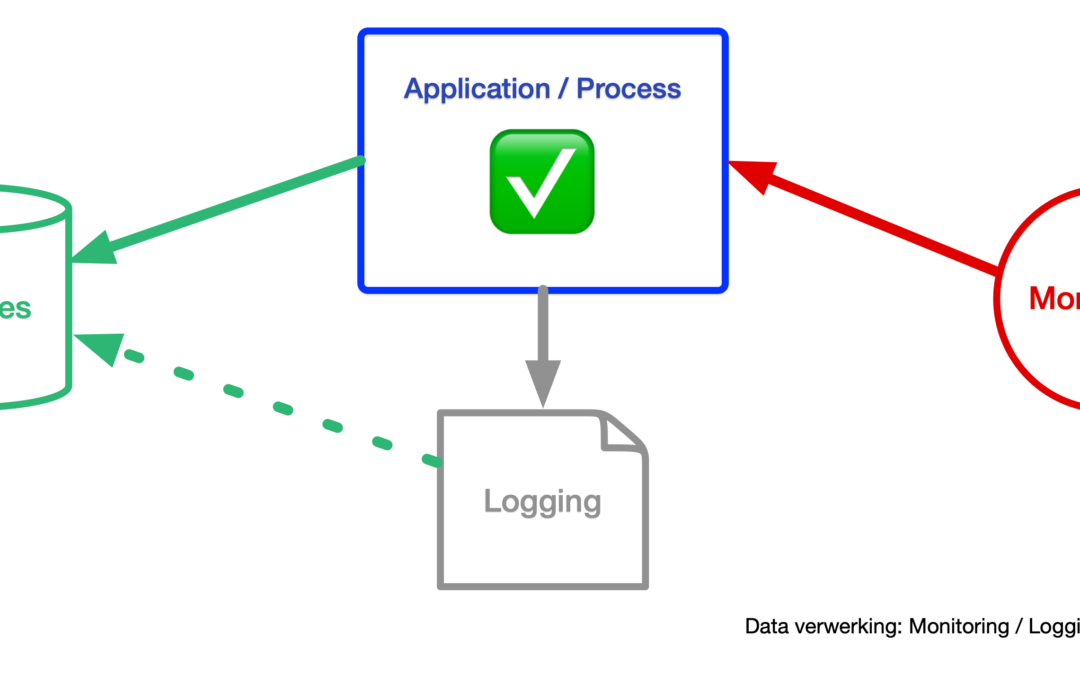
Uiteraard is er ook een oplossing voor als je beide vragen beantwoord met “niets” (geen dataverlies en altijd beschikbaar). Echter moet je dan een deel van het antwoord zoeken in de applicatie- en de procesarchitectuur en niet alleen binnen conventionele data opslag. Het simpelweg dubbel uitvoeren van cloud servers red je het ook niet mee maar oplossen kan uiteraard wel. Ga je voor de 24/7 oplossing kan dat met de technieken van vandaag de dag prima maar dan moet je goed kijken naar het ontwerp van je applicatie, en zonodig ook naar die van je klanten en of leveranciers.
Als er data tussen twee systemen heen en weer loopt, bijvoorbeeld tussen die van jou en van een andere partij. Wie is dan verantwoordelijk voor het herstellen of ‘altijd beschikbaar houden’ van die data en welke voorziening tref je dan. Ten eerste moeten contractueel dergelijke afhankelijkheden uiteraard goed op elkaar afgestemd worden. Denk als voorbeeld aan de uptime garanties vastgelegd in een SLA. Immers, als jouw leverancier jou 99,9% levert kan jij nooit 99,99% aan jouw klant leveren. Echter zijn de technische aspecten voor realisatie in deze context nog veel belangrijker.
Aldus hoe los je het technisch op? Je zal data moeten bufferen als het systeem aan de overzijde er tijdelijk niet is. Tevens zal je binnen je applicatie architectuur redundantie in moeten bouwen in de vorm van cluster technologieën voor de verschillende onderdelen. Vandaag de dag zijn er naast conventionele databases veel andere vormen van data opslag software, zoals message queueing en zogenaamde key/value stores, die dergelijke clustering al in zich hebben. Daarnaast zal je, in tegenstelling to conventionele monolitische applicatie opzet, een gelaagd modulair applicatie model moeten hanteren om dit te realiseren.
Hulp nodig bij risico analyse of robuuster maken van je bedrijfscontinuïteit? Neem gerust contact op.