Belangrijkste punten
Dit artikel beschrijft de vervanging van een verouderd monitoringsysteem door Grafana, met als doel verbeterde trendanalyses en systeemvergelijkingen mogelijk te maken. De belangrijkste aspecten zijn:
- Doelstellingen: Uitvoeren van betere trendanalyses, vergelijken van prestaties van systemen, applicaties en websites, koppelen van alarmmeldingen aan meerdere kanalen (zoals sms, Slack en WhatsApp), en inzicht bieden in lokale applicatie- en serverlogs zonder serverinlog.
- Uitdagingen: Behouden van bestaande monitoringfunctionaliteit, voorkomen van uitval in alarmeringsprocessen, en end-to-end transport van applicatie- en serverlogs naar een tijdreeksdatabase met behoud van originele gegevens.
- Oplossing: Een gefaseerde aanpak waarbij minder kritieke processen en data voor trendanalyses eerst naar het nieuwe systeem worden overgezet, gevolgd door bedrijfskritische onderdelen na bewezen robuustheid. Er wordt onderscheid gemaakt tussen historische monitoring (voor trendanalyses) en actieve monitoring (voor actuele systeemgezondheid).
- Resultaten: Het nieuwe systeem biedt diepgaand inzicht in systeem- en servicegedrag over verschillende perioden, ondersteunt capaciteitsplanning en detectie van conflicten na updates, en integreert nieuwe alarmkanalen zoals Slack.
De aanpak benadrukt modulariteit en flexibiliteit, met de mogelijkheid om systemen tijdelijk parallel te laten draaien voor validatie voordat volledig wordt overgeschakeld.
Introductie
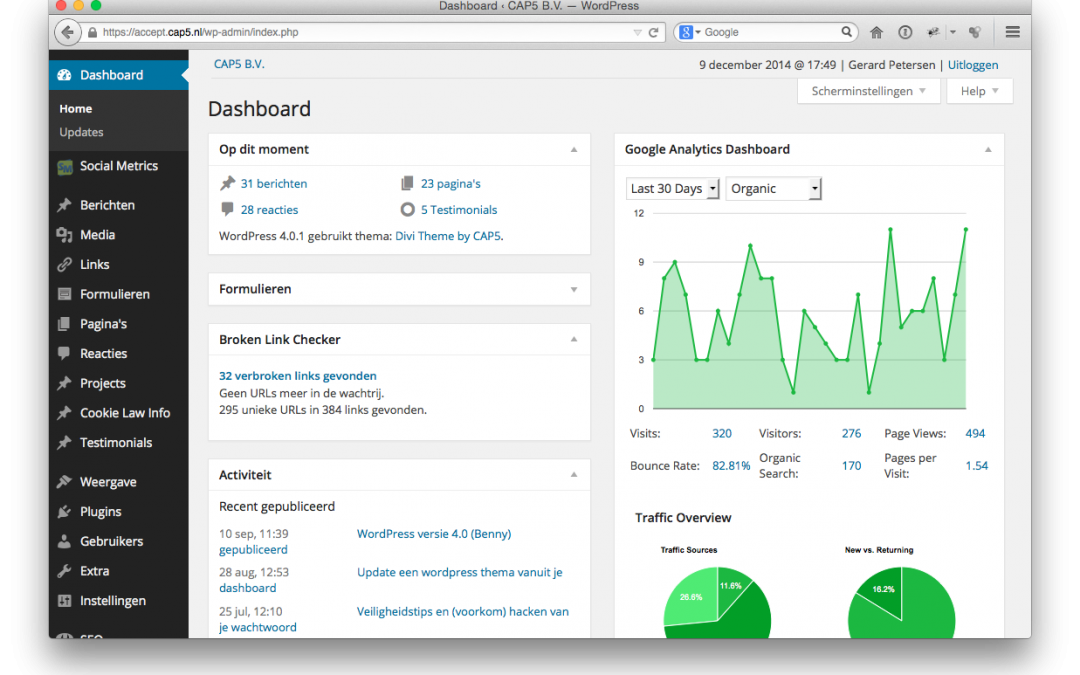
Dit project gaat over de vervanging van een verouderd monitoringsysteem met als doel kwalitatieve trendanalyses uit te voeren. Modern gereedschap als Grafana is daar bij uitstek geschikt voor. Daarmee kan een samengestelde grafische representatie gebouwd worden uit verschillende databronnen over verschillende tijdspannes. Zwaarwegend aspect is dat het een monitoringssysteem betreft waarover live alarmprocessen lopen. De sleutel tot goede uitvoer was dat de vervanging uitgevoerd moest worden met behoud van de huidige actieve bedrijfsprocessen.
Voorstelling van de klant
‘In control’ zijn op elk moment van de dag. We hebben over iedere willekeurige tijdspanne inzicht in wat onze platformen doen.
Het ging in dit geval om een intern project. Wij onderhouden applicatieplatformen en cloudinfrastructuur voor bedrijven, waaronder technologieleveranciers die SaaS-oplossingen bieden. Verder bewaken wij ook voor onze partners, waaronder marketingbureau’s, de servers waar hun klantenwebsites en applicaties draaien. Alles staat dus in het teken van veiligheid en continuïteit.
De doelen
De hoofddoelen van dit project zijn als volgt.
- Betere trendanalyses kunnen uitvoeren.
- Systeem, applicatie en websiteperformance van verschillende objecten met elkaar kunnen vergelijken.
- Koppelen van alarmoutput naar meerdere kanalen. Naast sms ook Slack en Whatsapp als outputkanaal inzetten.
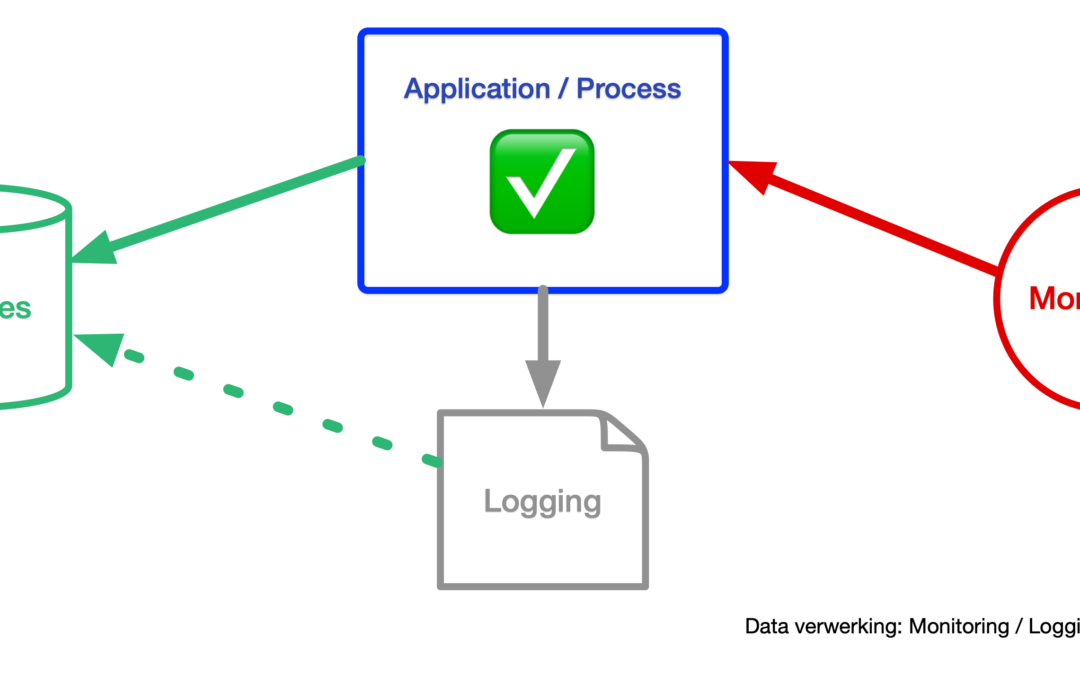
- De lokale applicatie- en serverlogging inzichtelijk maken in de analysetooling zodat serverlogins niet meer nodig zijn.
De uitdagingen
KPI’s die meewegen in het succesvol beschouwen van dit project:
- Bestaande monitoringfunctionaliteit moet mee in de nieuwe opzet.
- De alarmeringsprocessen mogen onder geen beding uitvallen.
- Applicatie- en serverlogging moet end-to-end getransporteerd worden naar een timeseries-database. Dit datatransport moet inhoudelijk getest en gevalideerd worden zodat alle originele gegevens bewaard blijven en inzichtelijk zijn in de analysetooling.
Oplossing
De aanpak en uitvoering moet zorgvuldig en grondig gedaan worden, omdat bij het uitvallen van bepaalde componenten de systeembewaking niet meer werkt. Omdat een deel van de monitoringprocessen cruciaal is hebben we voor een gefaseerde aanpak gekozen. De Prio1 en Prio2 (zie onder) serviceavailabilitychecks uit de huidige opzet blijven in de eerste fase op het bestaande systeem. De gemonitorde processen van lagere prioriteit en alle data(opslag) nodig voor trendanalyses zijn in de eerste fase al wel verhuisd naar het nieuwe systeem. Definities monitoring en responseprioriteiten:
- Prio1 – Direct 24/7
- Prio2 – Direct kantooruren
- Prio3 – Indien geen prio1’s en prio2’s
 Zodra de nieuwe tooling enige tijd in gebruik is en voor de langere termijn robuust genoeg blijkt, kunnen de bedrijfskritische onderdelen ook overgezet worden. Hiermee is het bestaande systeem afgeslankt, doordat zowel de metrische data als de opslag ervan is verplaatst. Daardoor zijn op een later tijdstip de Prio1- en prio2-monitoring- en alarmeringsprocessen makkelijker te porteren. We hebben geen migratie uitgevoerd van de bestaande historische data. De structuur ervan was dermate verschillend dat dit te veel werk op zou leveren met een onvolledig eindresultaat binnen de veel geavanceerdere nieuwe opzet. We hebben de keuze gemaakt om het nieuwe systeem enkele maanden parallel te laten draaien. Na voldoende ruwe data op het nieuwe systeem te hebben verzameld hebben we de datastromen op het oude systeem uitgezet. Dit is een keuze die enerzijds afhankelijk is van de waarde van de data versus anderzijds de complexiteit en verschillen in structuur en techniek van het oude en het nieuwe systeem. Ter verduidelijking, we maken hierbij onderscheid tussen twee vormen van monitoring.
Zodra de nieuwe tooling enige tijd in gebruik is en voor de langere termijn robuust genoeg blijkt, kunnen de bedrijfskritische onderdelen ook overgezet worden. Hiermee is het bestaande systeem afgeslankt, doordat zowel de metrische data als de opslag ervan is verplaatst. Daardoor zijn op een later tijdstip de Prio1- en prio2-monitoring- en alarmeringsprocessen makkelijker te porteren. We hebben geen migratie uitgevoerd van de bestaande historische data. De structuur ervan was dermate verschillend dat dit te veel werk op zou leveren met een onvolledig eindresultaat binnen de veel geavanceerdere nieuwe opzet. We hebben de keuze gemaakt om het nieuwe systeem enkele maanden parallel te laten draaien. Na voldoende ruwe data op het nieuwe systeem te hebben verzameld hebben we de datastromen op het oude systeem uitgezet. Dit is een keuze die enerzijds afhankelijk is van de waarde van de data versus anderzijds de complexiteit en verschillen in structuur en techniek van het oude en het nieuwe systeem. Ter verduidelijking, we maken hierbij onderscheid tussen twee vormen van monitoring.
- Historische monitoring – Verzamelen van metrische gedragsgegevens voor trendanalyses en meten van gedragsverandering bij applicatieaanpassingen of upgrades (je meet en ziet immers het gedrag in Grafana voor en na de aanpassing).
- Active state monitoring – Het controleren en bewaken van de actuele gezondheid van de gemonitorde objecten. Is de applicatie bereikbaar? Reageert het snel genoeg? Is er voldoende schijfruimte om uitval te voorkomen? Et cetera.
Zodra het nieuwe systeem in gebruik is kunnen er gradueel diversen monitoringobjecten overgezet worden van oud naar nieuw. De gekozen tool, namelijk Grafana in combinatie met de timeseries-database InfluxDB (kortweg TIG, link?), leent zich erg goed om alarmering op gemonitorde objecten aan te zetten. Hiermee kan je tijdens de overbruggingsperiode de bedrijfsprocessen live naast elkaar laten lopen en afdoende testen zodat continuïteit geborgd blijft. 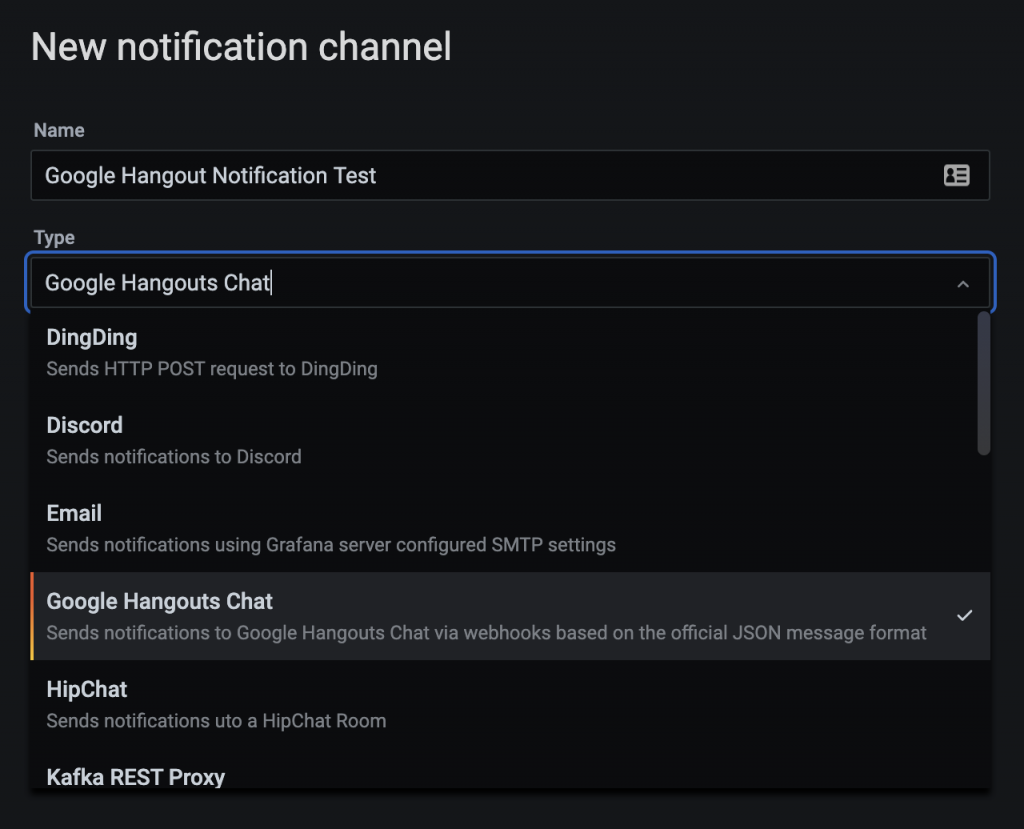 Daarnaast zijn er vanuit Grafana legio mogelijkheden voor het sturen van alarmeringsoutput over nieuwe kanalen. Personen of groepen kunnen bericht ontvangen via sms, mail, Slackkanalen et cetera. Daarnaast kan je ook nog eens tijdafhankelijk schakelen. Denk aan Slack tijdens kantooruren en sms daarbuiten.
Daarnaast zijn er vanuit Grafana legio mogelijkheden voor het sturen van alarmeringsoutput over nieuwe kanalen. Personen of groepen kunnen bericht ontvangen via sms, mail, Slackkanalen et cetera. Daarnaast kan je ook nog eens tijdafhankelijk schakelen. Denk aan Slack tijdens kantooruren en sms daarbuiten.
Resultaten
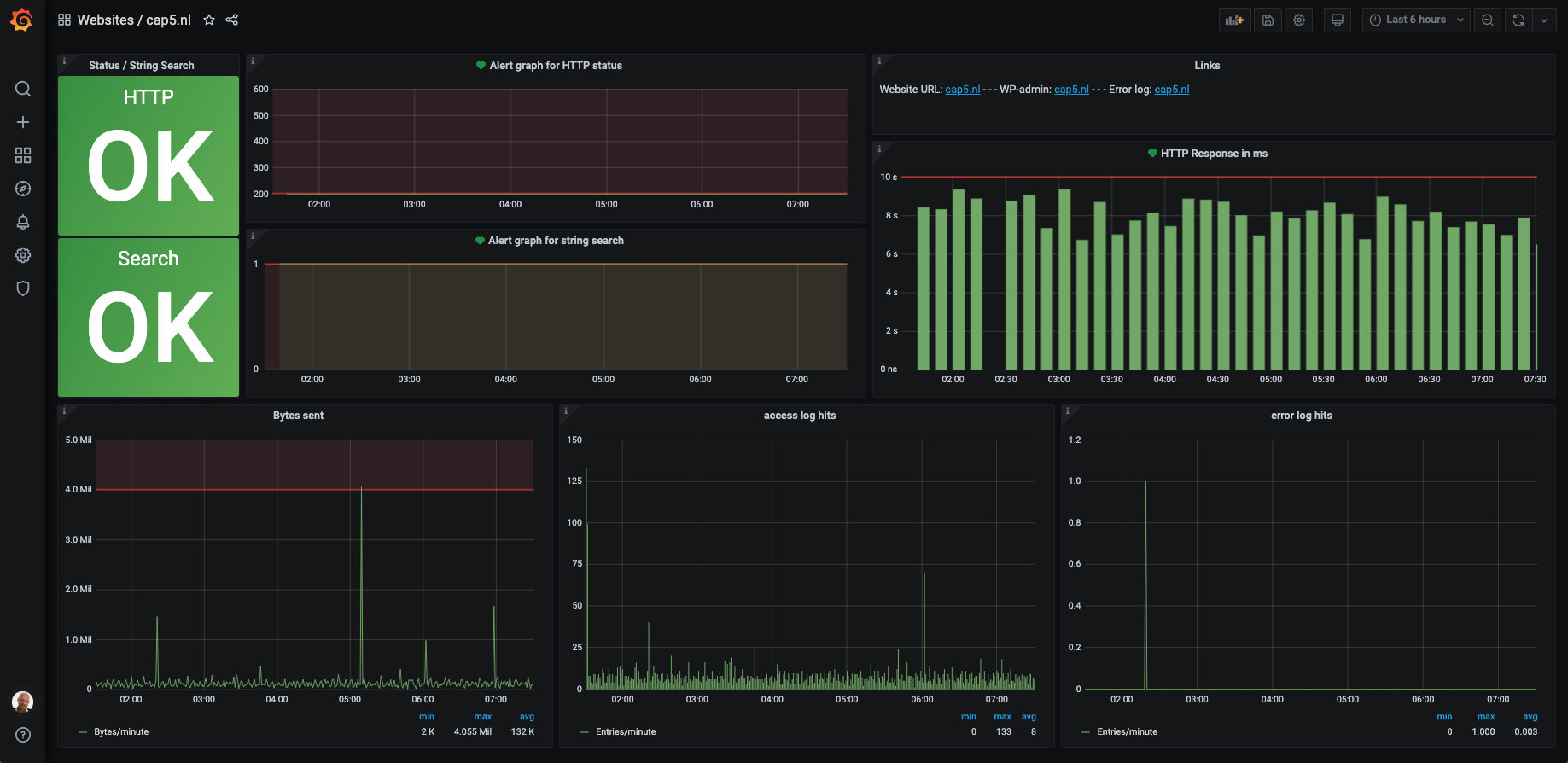
Het eindresultaat is een vergaande mogelijkheid tot het inzien en onderzoeken van het gedrag van systemen en services over vrij te kiezen perioden. Van vijf minuten tot de laatste vijf maanden of langer. Hiermee bestaat er, naast het analyseren van systeemimpact door bijvoorbeeld applicatieaanpassingen of toename van gebruikers over tijd, ook de mogelijkheid tot het doen van capaciteitsplanning ten aanzien van toekomstige groei. 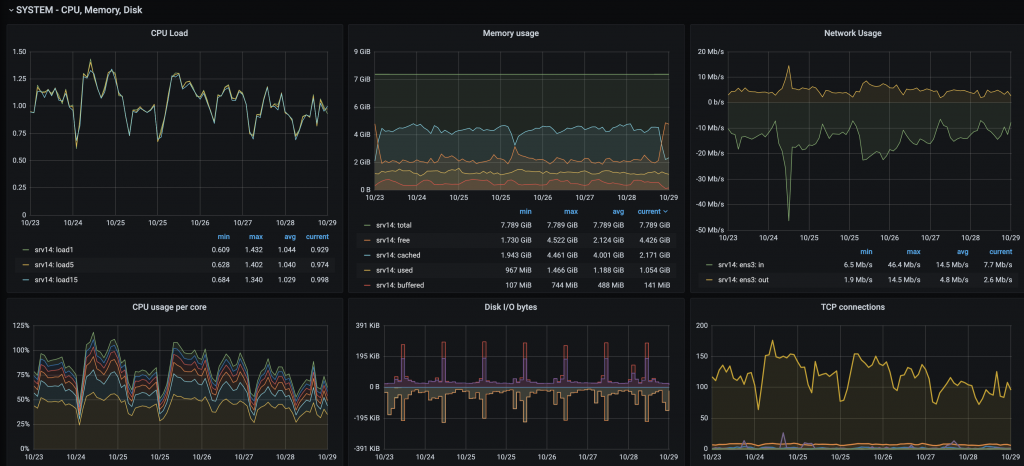 Dit geldt ook voor de nieuwe bewaking van websites. We hebben hier, doordat we ook logs op het nieuwe systeem binnenkrijgen, extra metrics in kunnen zetten. Naast de bekende ‘is de website bereikbaar’ en ‘wat is de responsetijd’ meten we nu ook de logcount per tijdseenheid. Is er bijvoorbeeld een plug-in-update geweest dan neemt de errorlogcount ineens toe. Zo weet je in een oogopslag dat er conflicten zijn in een website. Dit wordt uiteraard ook toegepast op de SaaS-oplossingen van onze klanten. Een van de nieuwe alarmoutputkanalen die is ingezet is Slack. Grafana rapporteert bij state changes van gemonitorde objecten direct naar een vooraf te kiezen Slack-kanaal.
Dit geldt ook voor de nieuwe bewaking van websites. We hebben hier, doordat we ook logs op het nieuwe systeem binnenkrijgen, extra metrics in kunnen zetten. Naast de bekende ‘is de website bereikbaar’ en ‘wat is de responsetijd’ meten we nu ook de logcount per tijdseenheid. Is er bijvoorbeeld een plug-in-update geweest dan neemt de errorlogcount ineens toe. Zo weet je in een oogopslag dat er conflicten zijn in een website. Dit wordt uiteraard ook toegepast op de SaaS-oplossingen van onze klanten. Een van de nieuwe alarmoutputkanalen die is ingezet is Slack. Grafana rapporteert bij state changes van gemonitorde objecten direct naar een vooraf te kiezen Slack-kanaal. 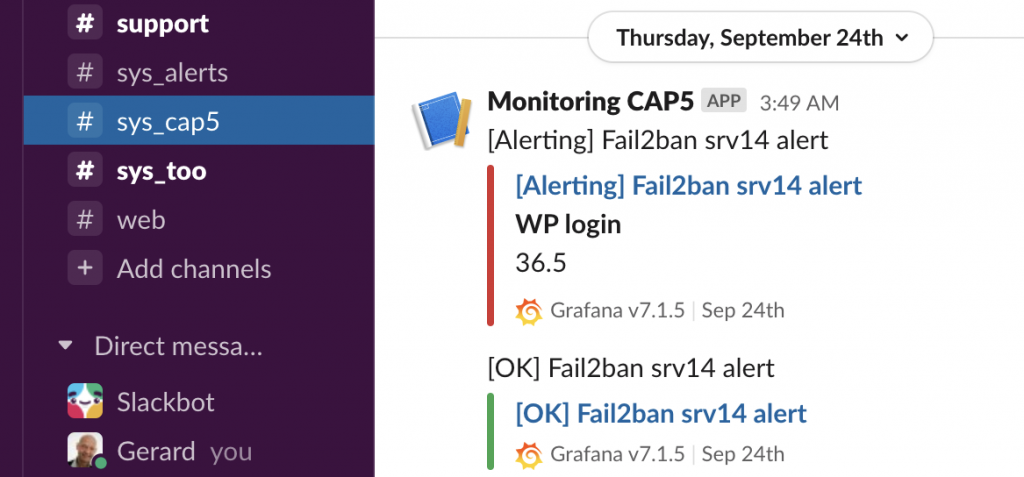 Daarnaast kan je eenvoudig nieuwe alarmering toevoegen en testen binnen Grafana. Stel je een nieuw alarm in, kan het op een test kanaal naar keuze aangezet worden. Als blijkt dat het werkt als verwacht, kan het daarna afdelings- of bedrijfsbreed ingezet worden. Daar waar het een bestaande alarmering betrof, kan je het vervolgens uitzetten op het oude systeem. Door zaken op deze manier gefaseerd uit te voeren en tijdelijk parallel te laten lopen kan je de overschakeling zeer gecontroleerd laten plaats vinden. Als er na verloop van tijd, in overleg met de klant vastgesteld wordt dat het nieuwe alarmeringsproces voldoende robuust is, kan het oude systeem permanent uitgefaseerd worden. Zo kan je dus ook de prio1- en prio2-servicebewaking gecontroleerd verhuizen. Hiermee wordt een 100% gegarandeerde continuïteit geborgd. Uiteraard zal, op basis van een het principe ‘continuous improvement’, het proces voortdurend verder getuned moeten worden op basis van de wensen van de klant. Met een beschreven aanpak als hierboven kan je systemen minder hecht geïntegreerd (de-coupled) inzetten. Deze verhoging van modulariteit geeft meer flexibiliteit in de toekomst. Ook is het tijdelijk parallel draaien een uitstekende manier om bedrijfsprocessen te valideren voor de volledige overstap te maken.
Daarnaast kan je eenvoudig nieuwe alarmering toevoegen en testen binnen Grafana. Stel je een nieuw alarm in, kan het op een test kanaal naar keuze aangezet worden. Als blijkt dat het werkt als verwacht, kan het daarna afdelings- of bedrijfsbreed ingezet worden. Daar waar het een bestaande alarmering betrof, kan je het vervolgens uitzetten op het oude systeem. Door zaken op deze manier gefaseerd uit te voeren en tijdelijk parallel te laten lopen kan je de overschakeling zeer gecontroleerd laten plaats vinden. Als er na verloop van tijd, in overleg met de klant vastgesteld wordt dat het nieuwe alarmeringsproces voldoende robuust is, kan het oude systeem permanent uitgefaseerd worden. Zo kan je dus ook de prio1- en prio2-servicebewaking gecontroleerd verhuizen. Hiermee wordt een 100% gegarandeerde continuïteit geborgd. Uiteraard zal, op basis van een het principe ‘continuous improvement’, het proces voortdurend verder getuned moeten worden op basis van de wensen van de klant. Met een beschreven aanpak als hierboven kan je systemen minder hecht geïntegreerd (de-coupled) inzetten. Deze verhoging van modulariteit geeft meer flexibiliteit in de toekomst. Ook is het tijdelijk parallel draaien een uitstekende manier om bedrijfsprocessen te valideren voor de volledige overstap te maken.
Advies nodig?
Loop je zelf met migratieuitdagingen? Wij kunnen je helpen op management niveau tot aan diep in de techniek. Neem voor een oriënterend gesprek contact met ons op. Tech ref (English): Auto-provisioning of website dashboards at scale with SaltStack and the Grafana API.