Belangrijkste punten
Table of Contents
- Belang van data – Het verkrijgen van inzicht in bedrijfsdata is essentieel voor een gezonde bedrijfsvoering, input gebaseerde sturing en het stimuleren van innovatie.
- Voordelen van een datalake – Een datalake biedt actuele informatie, faciliteert ad-hoc data-opvragingen, combineert verschillende databronnen en borgt de operationele continuïteit.
- Implementatie uitdagingen – Belangrijke is het vermijden van afhankelijkheden tussen verschillende (database)systemen en het flexibel blijven voor toekomstige uitbreiding.
- Oplossingsstrategie – Een goede aanpak omvat database-agnostische replicatie en een gecompartimenteerde toegangscontrole tot de verschillende data bronnen.
- Gekozen ontwerp – Het ontwerp ondersteunt gecontroleerde toegang per dataset en integreert met diverse beheer- en analysetools zoals Dataiku, Grafana en PG Admin.
Introductie
Het project dat we hier beschrijven, gaat over het inrichten van een datalake, ook wel bekend als een datawarehouse, voor een van onze klanten. Dit artikel laat zien hoe belangrijk inzicht in je bedrijfsdata is, vandaag de dag noodzakelijk gereedschap voor een gezonde bedrijfsvoering. Je leest hoe je dit opzet, welke uitdagingen je tegenkomt, wat het je oplevert, hoe het de beslissingseffectiviteit verhoogt en de operationele continuïteitsrisico’s verlaagt.
Situatieschets
De opdrachtgever in deze projectcasus betreft een tech-scale-up, een organisatie met een scala aan diensten met elk hun eigen productieplatform. Vanuit de verschillende platformen, zowel intern als extern, moet data slim ingezet worden, om continu tot innovatieve en optimale kwaliteit van diensten te komen. Dit kan alleen als je data goed inzichtelijk maakt en kan combineren over de verschillende platformen heen.
Voordelen
De voordelen om voor een dergelijke datalake-oplossing te kiezen in deze snel veranderende tijden zijn legio.
- Het kunnen leveren van actuele informatie aan – interne en externe –klanten over de afname van diensten en het gebruik ervan, op basis van realtime data.
- Het faciliteren van smart en ad hoc opvragen van data zodat de datascience-afdeling snel informatie en rapportages op maat kan leveren aan interne klanten.
- Ruimte voor ‘pick and choose’ van nieuwe databronnen en de mogelijkheid om deze slim te combineren.
- Toegepaste dataverrijking verwerken en behouden uit verschillende interne en externe bronnen voor toekomstige innovaties en leveren van nieuwe diensten.
- Operationele continuïteit borgen van bestaande productiediensten, terwijl je tegelijkertijd een omgeving hebt voor data-onderzoek.
Uitdagingen
De uitdagingen in dit project zijn met name van (bedrijfs-)operationele aard. Immers, alle gereedschappen die gebruikt worden zijn goed onderhoudbaar. De kunst is flexibel te blijven voor toekomstige wensen en innovaties. Hieronder een aantal aspecten waar rekening mee gehouden moest worden.
- Conventionele databasereplicatie is geen optie, omdat hierbij een afhankelijkheid bestaat tussen het type brondatabase en het type doeldatabase. Je kan immers niet zomaar MySQL repliceren naar PostgreSQL, laat staan dat je bijvoorbeeld Google Spreadsheets kan inlezen.
- Er is een zo generiek mogelijke opzet nodig voor duurzaam beheer, waarbij tegelijkertijd zo veel mogelijk flexibiliteit wordt behouden om in nieuwe behoeften te kunnen voorzien.
- Berekende resultaatdata moet niet steeds opnieuw worden gegenereerd of tijdelijk opgeslagen, maar continu beschikbaar zijn.
- Bij het maken van een back-up moet alleen dat worden meegenomen wat nieuw is en wat (eventueel) hersteld moet kunnen worden. Gekopieerde data uit andere systemen hoeft niet in de back-up te worden meegenomen, wat die data bestaat al en/of is regenereerbaar. Dit slim oplossen resulteert tevens in kostenreductie, wat het ict-budget ten goede komt.
Oplossing
Om alle uitdagingen het hoofd te kunnen bieden is er o.a. gekozen voor een database-agnostische replicatie, maar daarover zo meer. Daarnaast is er een dataontwerp opgezet waarmee we datasets uit alle live-systemen flexibel kunnen samenstellen. Er is tijdens het ontwerp met de volgende aspecten rekening gehouden:
- Er is gekozen voor een gecompartimenteerde structuur die een hoge mate van (toegangs-)controle en flexibiliteit biedt.
- Er is ruimte voor aparte datasets van acceptatie- en productie-omgevingen, zodat nieuwe analyses en queries eerst getest kunnen worden op acceptatiedata en -systemen, voor de wijzigingen worden doorgevoerd op productie(-data).
- Er kan heel specifiek worden gekozen van welke data we back-ups maken. Bij grotere hoeveelheden data is dubbel back-uppen immers een onnodige kostenpost.
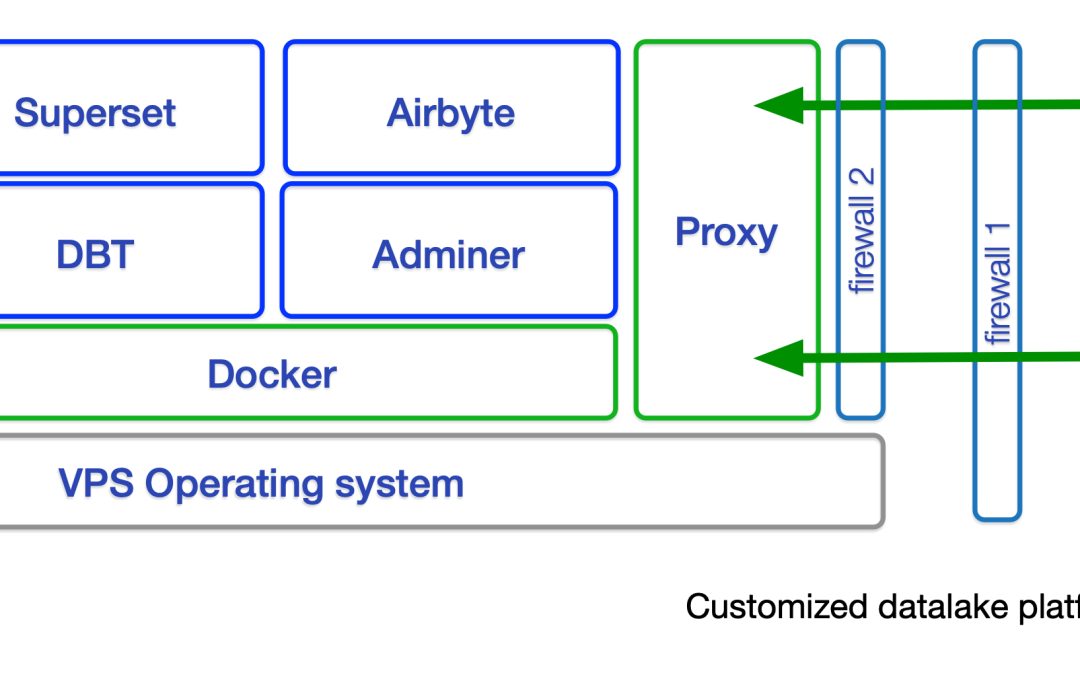
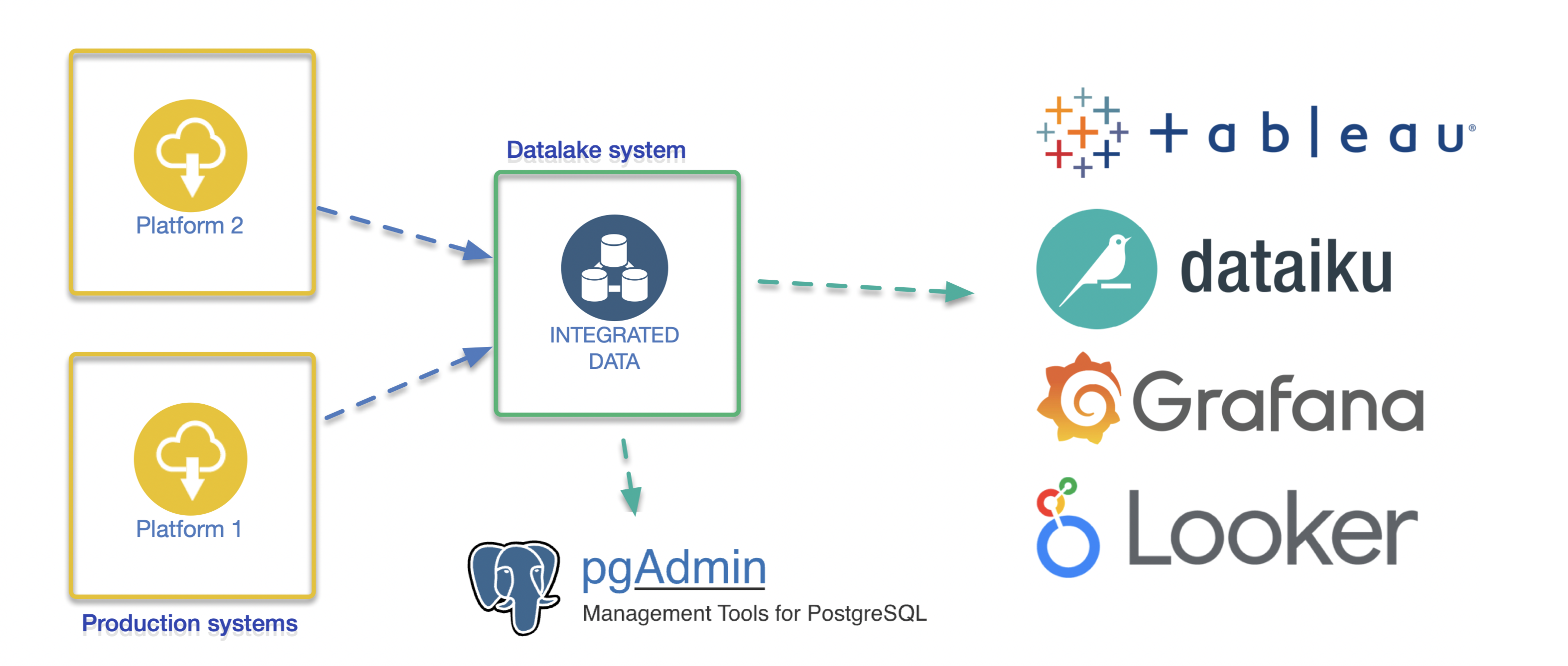
- De aard van het ontwerp ondersteunt gecontroleerde toegang per dataset met een diversiteit aan beheer- en analysetools. Denk hierbij aan Dataiku, Grafana, maar ook low-level-beheertools als PG Admin. Ook is er de mogelijkheid om een veilige koppeling te maken met externe rapportagetooling als Looker en Tableau. (Ref: link link)
Structuur en schaal
In eerste instantie was de opzet een kopie per productiedatabase, met daarop diverse monitoring- en back-up-tools. Dit wordt met Saltstack allemaal generiek schaalbaar geprovisioned.
Vervolgens, omdat het ontwerp met enthousiasme ontvangen werd, hebben we een periode intensief contact gehad met de datascience-afdeling. Na een eerste review van de opzet bleek uiteindelijk dat we een extra abstractielaag in de structuur nodig hadden. De oorzaak was dat de applicaties op de productiesystemen opgebouwd zijn uit zogenaamde microservices. Omdat deze microservices weliswaar aan elkaar relateren binnen een platform, maar elk hun eigen database-back-end hebben, was het noodzakelijk deze data te combineren binnen de datalake. De oplossing hiervoor was de inzet van schema’s binnen de verschillende databases aan de datalakezijde.
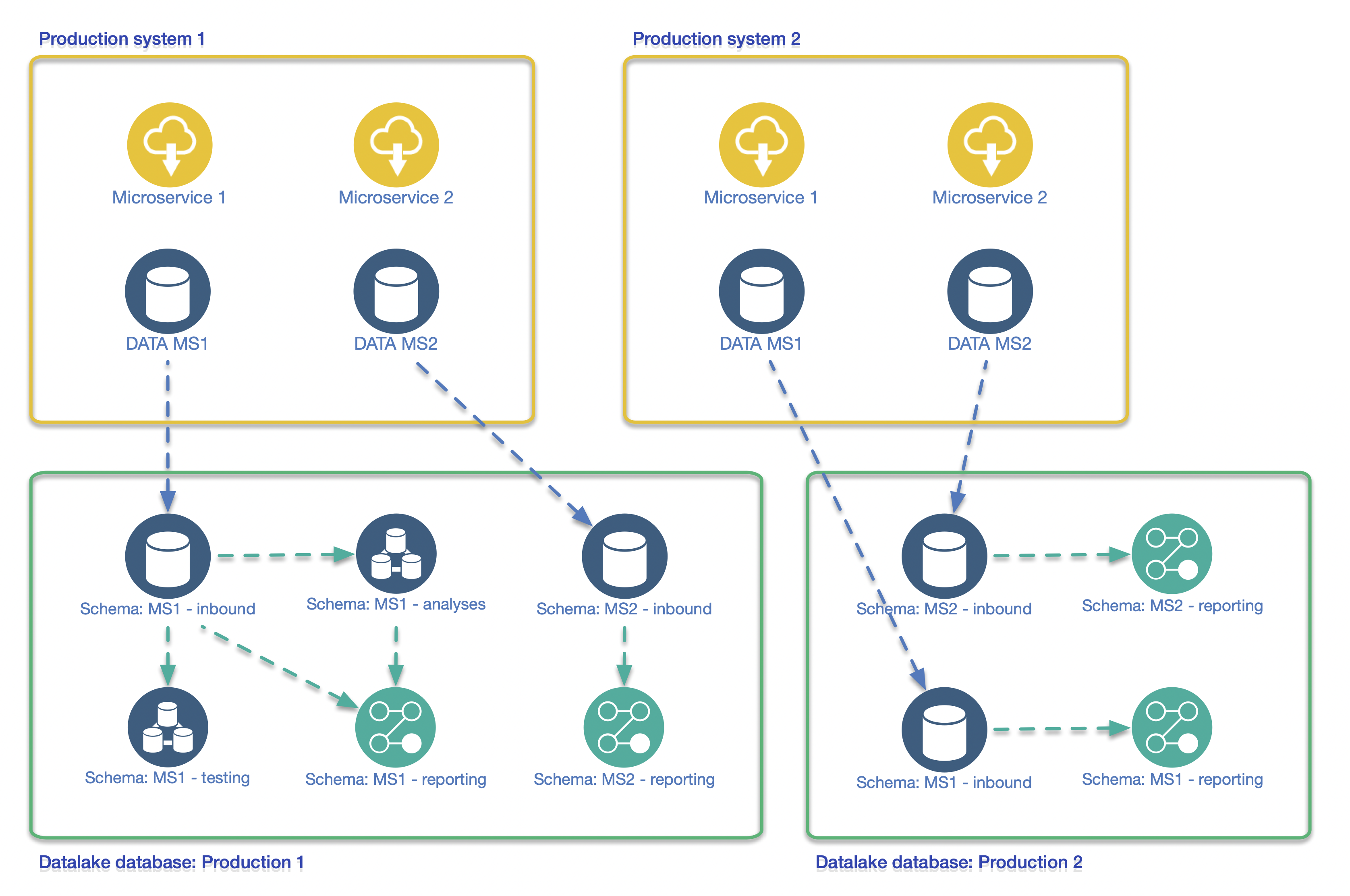
Datalake schema design with Microservices
Doordat we binnen de databases de schema’s geïmplementeerd hebben, heeft men meer flexibiliteit. Daardoor is het eenvoudiger om data te combineren tussen de verschillende microservices. Dit heeft een extra ontwerpslag opgeleverd omdat het inzetten van schema’s ook doorgevoerd moest worden op de aanleunende systemen. Denk hierbij aan monitoring, back-up-methodiek en uiteraard de replicatie-opzet zelf. Of je schema’s van meet af aan in moet zetten, hangt erg af van de schaalgrootte, de toekomstwensen, de klantkennis (met name bij de datascience-afdeling) en de complexiteit van de productiesystemen die je wilt repliceren naar het datalake-platform.
Replicatiemechanisme
Er is een belangrijk detail m.b.t. het repliceren van databases. Ten eerste wilde de klant een verscheidenheid aan databronsoorten en daarmee verschillende databasetypen repliceren. Echter ook data die verkregen wordt door het pollen van externe api’s. Database-eigen replicatiemechanismen die alleen eigen Master → Slave-replicatie ondersteunen, zijn hierdoor onbruikbaar. De requirements m.b.t. de replicatietooling bestonden dus uit een framework dat hier wel mee overweg kan.
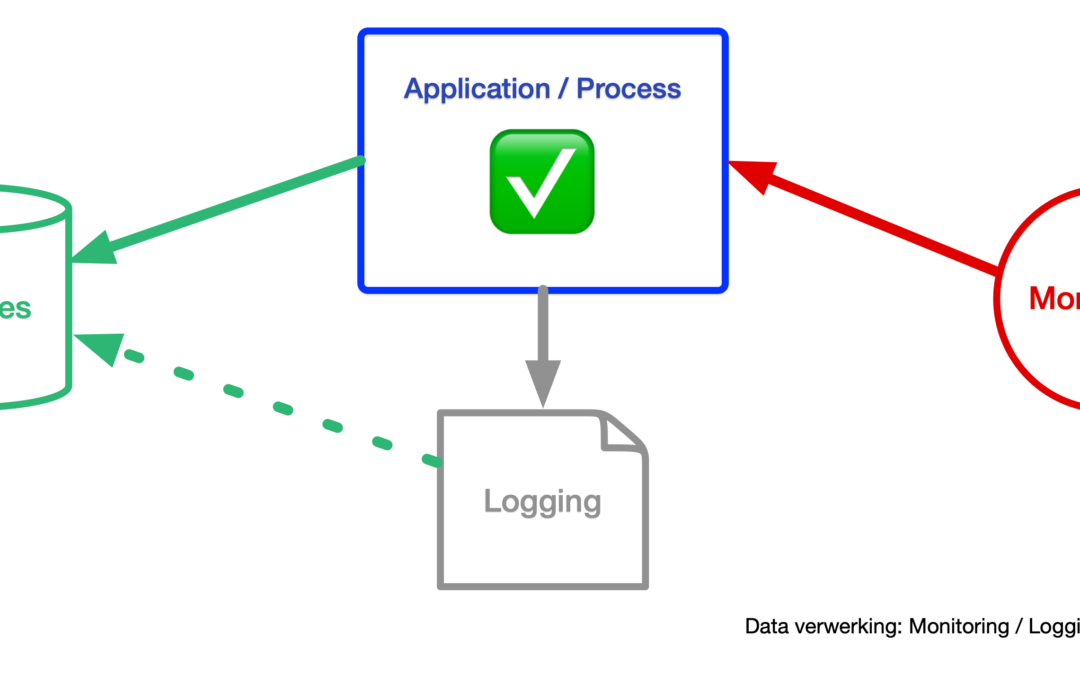
Tech info: Er is een belangrijk aspect wat bij reguliere databasereplicatie roet in het eten gooit. PostgreSQL (maar ook bijvoorbeeld MySQL) heeft een eigen implementatie van transactionele logging, genaamd Write Ahead Log of WAL. Dit is een superrobuust mechanisme om databases te repliceren en wordt vaak geïmplementeerd in databaseclusters. De meest simpele vorm is de Master → Slave-opzet. Het nadeel hierbij is echter dat men aan de Slave-kant geen mutaties kan uitvoeren op de database omdat dit de logging verstoort. De chronologie in de transacties raakt dan van slag waardoor het replicatiemechanisme breekt en hersteld moet worden.
Om de verschillende databronnen realtime binnen te halen en niet aan de database-eigen mechanismen vast te zitten, is er gekozen voor een database-agnostische replicatie op basis van het singer.io-framework. Voor provisioning van zowel het datalakesysteem als de replicatietooling is gebruik gemaakt van de configuration-management and orchestration-tool Saltstack. De hierin ontworpen modellering en datastructuur is volledig generiek en per datastroom configureerbaar.
Controle en veiligheid
Als de datalake opgezet is, komt daar een scala aan datastromen binnen. Om deze data zinnig in te kunnen zetten hebben mensen door middel van tools toegang nodig. Data-scientists willen immers op detailniveau met de data aan de slag. Maar ook management of marketingafdelingen willen op een hoger, logisch niveau dashboards kunnen opzetten.
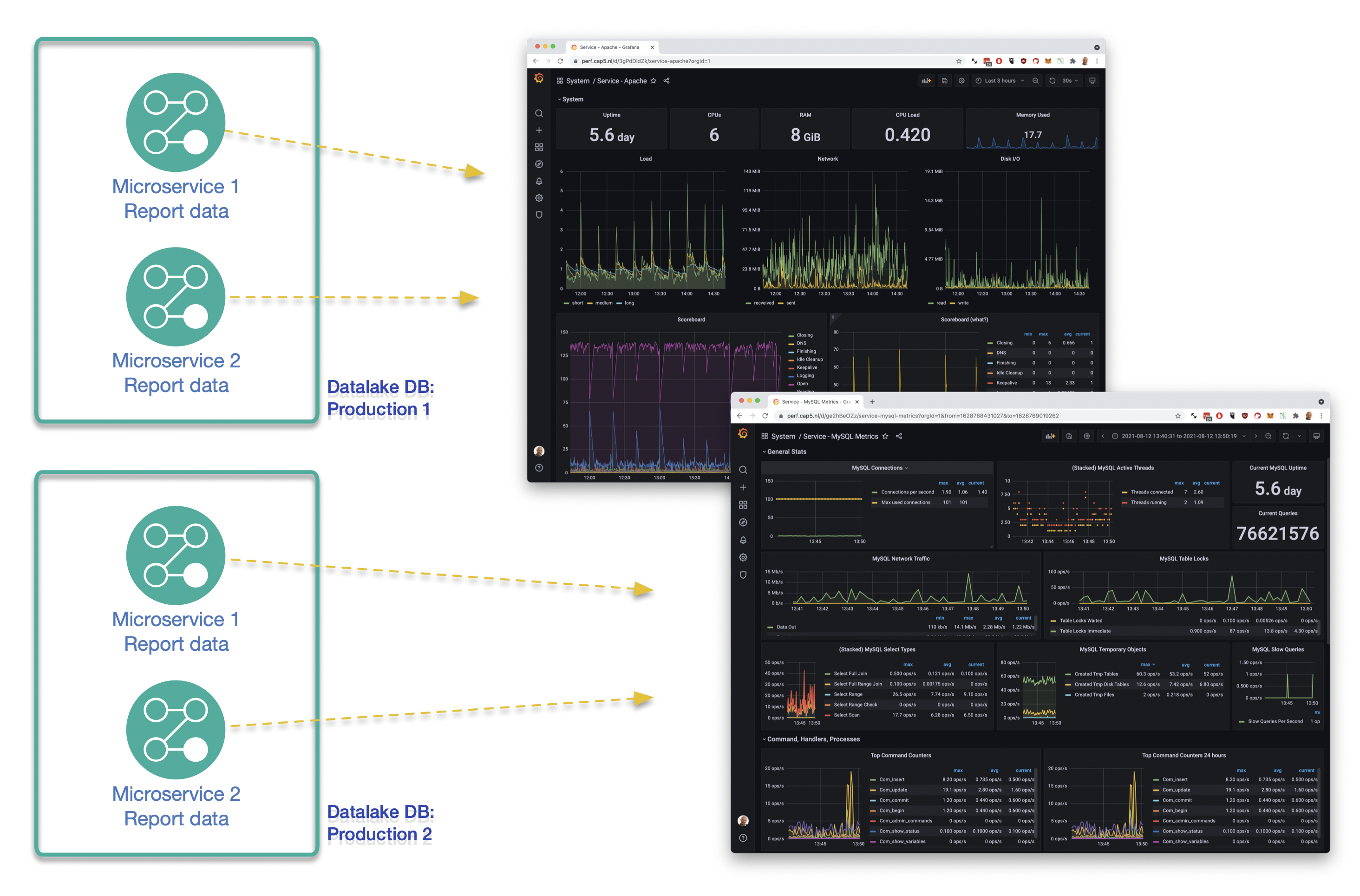
Datalake reporting datasets en dashboards
Je creëert als het ware vensters op de verschillende datasets of combinaties daarvan. Door de gekozen opzet is er ten eerste per dataset accountbeheer mogelijk. Met behulp van de tweede laag kan men accountbeheer ook delegeren en uitschalen. Tenminste: als men tooling kiest die accountmanagement faciliteert. Software als Grafana, Dataiku en vergelijkbaar beschikken over accountmanagement, waarmee databronnen geïsoleerd en aan accounts gekoppeld kunnen worden. Omdat we diverse beheertools op de datalake ingezet hebben, beschikken de datascientists uiteraard ook over een low-level-tool als PG Admin.
De structuur zoals die ontworpen is faciliteert toegang per dataset, waardoor er ook op een veilige manier koppelingen mogelijk zijn met externe rapportagetooling als Looker en Tableau. Door de juiste toolkeuze te maken die klopt met de klantbehoefte, werkt de implementatie zeer autonoom en is er minimale tussenkomst van operationele afdelingen of beheerders nodig.
Gebruik en continuïteit
Hoewel het hier geen primaire productiesystemen betreft, is de beschikbaarheid wel degelijk belangrijk. Een datalake levert immers vaak realtime feeds voor company-dashboards. Afhankelijk van de belangrijkheid van de getoonde informatie kan besloten worden verdere redundantie of caching aan te brengen in het datalake-cluster. Hier kan men een kosten-baten- en risico-analyse op uitvoeren. Twee bekende aspecten om dit vast te stellen zijn het bepalen van de acceptabele hersteltijd bij uitval en de hoeveel data waarvan men het acceptabel vind om te mogen verliezen. Beter bekend als Recovery Time Objective en Recovery Point Objective.
Een ander positief aspect dat de datalake heeft, is de continuïteit van primaire productiesystemen. Zware databevragingen of calculaties kunnen impact hebben op de performance. Door dit te doen op het datalakesysteem zullen klanten die de productieservices gebruiken hier geen enkele hinder ondervinden.
Resultaten
Het opgeleverde datalakesysteem is een goed onderhoudbare, veilige en flexibele omgeving die een rijkdom aan zinvolle data oplevert en voor vele doelen inzetbaar is. Het is een onmisbaar bedrijfsonderdeel dat uit alle platformen realtime (gecombineerde) data aanbiedt aan interne en externe klanten. Daarnaast biedt het een uitstekende omgeving voor test- en onderzoeksdoeleinden.
Hieronder de belangrijkste aspecten op een rij:
- Mogelijkheid tot gebruik van product- en klant-platforminformatie, zodat het management kan sturen op bedrijfsgroei en innovatie.
- Realtime dashboards voor marketing om bij nieuwe campagnes nauwgezet te monitoren welke invloed zij hebben op platformgebruik.
- Het automatisch leveren van maandelijkse rapportages door de datascience-afdeling aan interne en externe klanten over het gebruik.
- Het ad hoc kunnen leveren van maatwerkrapportages en -presentaties voor sales- en marketingdoeleinden, maar ook voor verbetering van bestaande platformen.
- Een onderzoeksomgeving waar tijdelijk databronnen gecombineerd kunnen worden tot nieuwe datasets voor productontwikkeling en innovatie.
- Men kan veilig en beheersbaar een scala aan moderne tooling inzetten als Grafana, Dataiku, PG admin om data direct inzichtelijk te maken
- Er kunnen zonder productie-service-onderbreking databases van diverse aard gecombineerd en opgezet worden. Denk aan relationele-, timeseries- of object-databases.
- Door een datalake heeft men de mogelijkheid om data, verrijkt via externe SaaS-diensten, zelf op te slaan. Hierdoor worden extra externe calls geminimaliseerd en kunnen kosten worden gereduceerd.
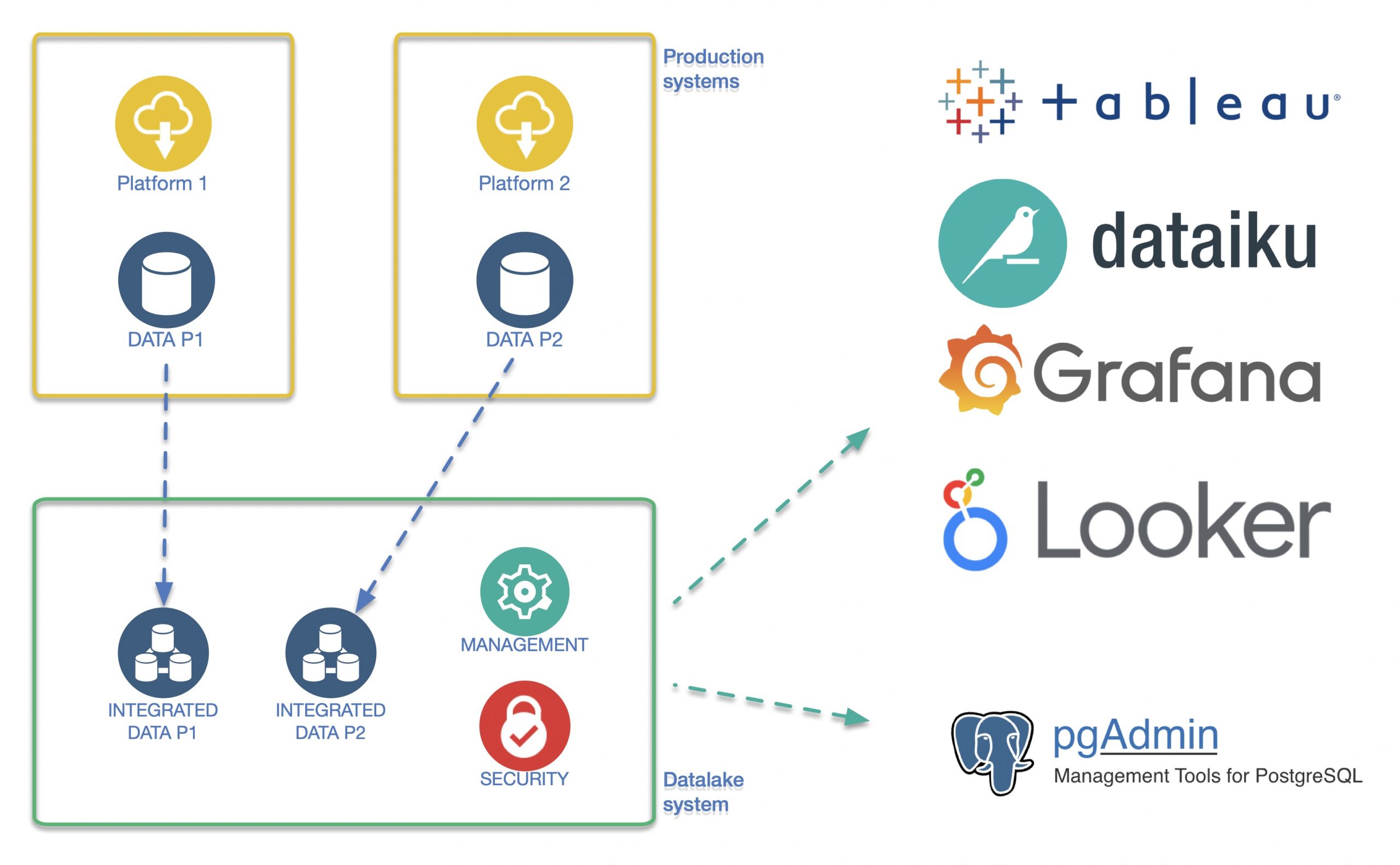
Genoemde data tooling:
- Tableau – https://www.tableau.com/
- Grafana – https://grafana.com/
- Dataiku – https://www.dataiku.com/
- Looker – https://looker.com/
- PG Admin – https://www.pgadmin.org/
Uiteindelijk is een datalake onontbeerlijk voor elk mid- tot high-scale mkb-bedrijf. Het is immers een tool voor informationdriven management en een onderzoeksomgeving voor het toetsen van nieuwe innovaties.
Heb je naar aanleiding van deze casus vragen of hulp nodig bij het verbeteren van je datahuishouding? Wij kunnen je hierbij helpen. Plan een call in.